Plain text is a series of characters delimited into lines by newline (LF, line feed) characters. You can send this text directly to a terminal window with a utility like cat(1). There are no hidden formatting codes; it’s “just the text, ma’am.”
Before the puns get any worse, let’s dig in!
Quick Review
As you saw in the previous column (if you didn’t see the column, you might want to review it), to start a new line at any point in plain text, simply insert a newline character. To join two lines, remove the newline between them — and maybe add a space or TAB character to separate them.
When a terminal or printer reads a TAB character, it moves the current position to the next tabstop. TAB characters are also used as field separators; you can make a simple database with TABs between the fields and a newline at the end of each record.
Linux utilities can also reformat text that doesn’t contain TABs. We’ll see examples of that, too.
Lots of Possibilities
Many GNU utilities started in the days of Unix — back when a tty really was a teletype. Without a graphical display (or a graphical editor) to rearrange text, programmers came up with many ways to slice, dice, and reassemble data from scripts and the command line.
We’ll see some of those ways: Enough ways, I hope, that people new to this way of handling text will be ready to find other ways — and gurus will still get a few surprises.
Starting with a Spreadsheet
Plain text can come from lots of places, including:
- The output of a utility (grep, for instance),
- Text saved from an application (see Figure One for an example),
- Text pasted into a terminal window from a graphical application, as in Figure Two near the end of this article.
Note that some of this text may not be “plain” characters. For instance, if you’re copying from a web page designed by a Macintosh user, the designer may have unwittingly included the Macintosh encoding of a special character (maybe a “curly quote”) that isn’t recognized on your Linux system.
For the first few examples, let’s use an OpenOffice.org spreadsheet file saved as plain text. (On the File menu, choose Save As, type Text CSV.) Assuming that the data doesn’t contain any TAB characters, you can set the Field Delimiter to TAB and the Text Delimiter to none (delete the default quote mark in that dialog box). Figure One shows this.
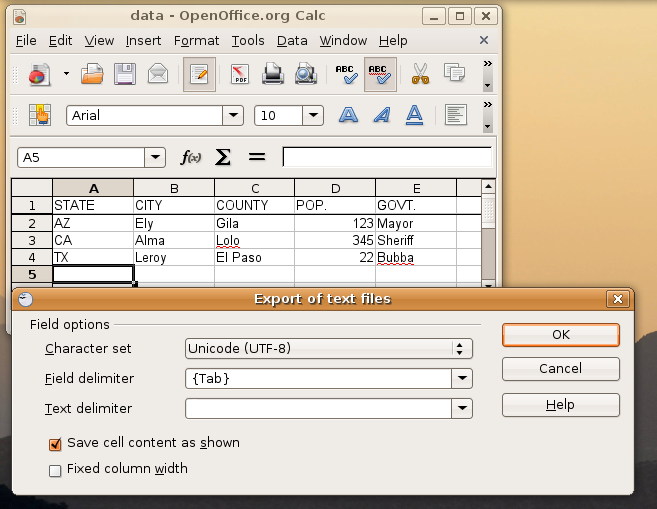
Figure One: Saving a spreadsheet as plain text
Below are are two views of the resulting file data.txt (renamed from the default data.csv). First, plain cat outputs the TAB characters between fields, which the terminal displays by moving to the next tabstop position. Next, cat -tve shows what’s actually in the file:
$ cat data.txt STATE CITY COUNTY POP. GOVT. AZ Ely Gila 123 Mayor CA Alma Lolo 345 Sheriff TX Leroy El Paso 22 Bubba $ cat -tve data.txt STATE^ICITY^ICOUNTY^IPOP.^IGOVT.$ AZ^IEly^IGila^I123^IMayor$ CA^IAlma^ILolo^I345^ISheriff$ TX^ILeroy^IEl Paso^I22^IBubba$
Checking the data file with cat -tve or od -c is a good idea. They’ll reveal “hidden” or “non-plain” characters buried in the data. Notice the space character in the field El Paso. Because the field separator is a TAB, the space doesn’t cause any problems.
Utilities that Understand TABs
Scripting languages (Perl, awk, .) can parse and write TAB-separated data. Table One lists some other Linux utilities that handle TABs.
Table One: Some utilities that understand TABs
| Utility | Description |
|---|---|
| cut(1) | Remove sections from each line of files |
| echo(1), printf(1) | Write arguments to standard output (\t makes a TAB) |
| expand(1), unexpand(1) | Convert TABs to spaces, spaces to TABs |
| paste(1) | Merge lines of files into TAB-separated output |
| sed(1) | Stream editor |
| sort(1) | Sort data by one or more of its fields |
Whether your data comes from a spreadsheet or some other source, if you can massage your data into TAB-separated fields, the examples below can help you slice and dice it. Examples toward the end of the article cover other types of data.
(If your data is in spreadsheet format, the tools built in to the spreadsheet program — including built-in macros and programming — may do the job. But imagine you have 200 spreadsheets, each with 50 columns to rearrange. Assuming that the spreadsheet’s built-in tools can do the job, do you really want to make all of those edits with a mouse and a bunch of dialog boxes? Or would you rather write a little loop from a shell prompt that edits automatically?)
Rearranging Fields with cut
The handy cut(1) utility separates text into fields, then outputs the fields you select. The default field delimiter is TAB; the -d option changes that. List the output fields after the -f option. The field list is one or more numbers, starting at 1; separate individual field numbers with a comma (,) or give a range of fields with a dash (M-N). A range can be incomplete: -N means fields 1-N, and M- means fields M through the last. Here are a few examples with our sample data file:
$ cut -f1,5 data.txt STATE GOVT. AZ Mayor CA Sheriff TX Bubba $ cut -f5,1 data.txt STATE GOVT. AZ Mayor CA Sheriff TX Bubba $ cut -f3- data.txt | cat -vte COUNTY^IPOP.^IGOVT.$ Gila^I123^IMayor$ Lolo^I345^ISheriff$ El Paso^I22^IBubba$
As you can see, cut ignores the order of field numbers after -f. To output the fields in a different order — for instance, to rearrange columns from a spreadsheet — you need a better tool. One is awk(1). Let’s enter everything from the command line: set the input and output field separators to TAB, then print the input fields 4, 3, 5, 2, and 1:
$ awk -F '\t' -v 'OFS=\t' '{print $4, $3, $5, $2, $1}' data.txt
POP. COUNTY GOVT. CITY STATE
123 Gila Mayor Ely AZ
345 Lolo Sheriff Alma CA
22 El Paso Bubba Leroy TX
Of course, you can use your favorite scripting language (if it isn’t awk). and that includes a shell. Here are two bash scripts — which you could also enter from the command line if you’d rather. They both set IFS, the shell’s internal field separator, to a TAB character while using read to read a line of data from the standard input. The -a option writes the fields into the array $f. Then echo outputs the fields in the order we want.
Listing One: Reordering fields with bash, version 1
#!/bin/bash
# Set $IFS to TAB only during "read":
while IFS=" " read -r -a f
do echo -e "${f[3]}\t${f[2]}\t${f[4]}\t${f[1]}\t${f[0]}"
done
The script in Listing One has a couple of problems. One is that it uses echo -e to interpret the \t (TAB) escape sequences. If any of the data fields contain a backslash (\), too, echo may interpret those — and corrupt the data. The other problem is that, if your data has a lot of fields, passing a long list of arguments to echo is ugly and tedious.
The version in Listing Two uses nested loops. The inner for loop steps through all field numbers except the last, using echo -En to print the field contents and a TAB — without any backslash interpretation, and without a final newline. After the for loop finishes, a final echo -E outputs the last field and a newline:
Listing Two: Reordering fields with bash, version 2
#!/bin/bash
# Set $IFS to TAB only during "read":
while IFS=" " read -r -a field
do
for n in 3 2 4 1
do
# Embedded TAB at end of string:
echo -En "${field[n]} "
done
echo -E "${field[0]}"
done
All three scripts above show a specific example of a general technique for rearranging data on a line: split the line into pieces (at TABs or some other place), then output those pieces in the order you want.
Modifying Some Lines
The techniques in this section are obvious, but worth mentioning. How can you output only certain input lines?
- If you can write a regular expression to match the lines you want, try grep or egrep.
- Using sed -n tells sed to output only the lines you choose (instead of the default, which is to output all lines). For instance:
- sed -n '13,$p' outputs lines 13 through the end of input.
- sed -n '/start/,/end/' outputs all lines between one containing start and one containing end.
- sed -n '10p;22p;93,95p' outputs lines 10, 22, 93, 94, and 95.
- Of course, you can do more. Making a sed script file is sometimes simpler than typing long expressions at a shell prompt.
- Use a scripting language with a patern match. For example, here’s an awk expression that outputs a record only if the second field contains this:
$2 ~ /this/ {print $4, $3, $5, $2, $1}
Reordering Lines
Scripting languages can also reorder lines (or, in database terminology, records). (Because the lines need to be buffered or read from a temporary file, not all utilities are designed to reorder lines.) The GNU version of sort has a lot of ways to sort data — including random order (!) with sort -R.
Modern versions of sort use the -k option to specify sort fields. But how can you sort on the last word (field) in a line, if lines don’t all have the same number of words? Here’s a trick: copy the last word to the start of the line, sort on the first field in that temporary line, then strip off the first field. Watch:
$ cat salaries
Yvette van der Hoff 100000
Barack Obama 400000
Bernie Madoff 0
John Q. Public 20000
$ awk '{print $NF, $0}' salaries | sort -nr -k1,1 | cut -d" " -f2-
Barack Obama 400000
Yvette van der Hoff 100000
John Q. Public 20000
Bernie Madoff 0
Re-flowing Text with fmt
The fmt utility reads words, separated by spaces, and outputs them reformatted into lines of approximately equal width. There’s an introduction in the section “Data Chunking with fmt” of the article More Data Surgery.
A not-so-obvious use of fmt is converting a paragraph from a group of newline-terminated lines (with “hard” line breaks) into a single long, wrapped line (“soft” line breaks). This can be very handy with copy-and-paste from one program to another. For instance, an email message often appears as a bunch of newline-terminated lines. If you copy and paste those “jagged” lines into another window, such as a word processor, the lines won’t flow smoothly into a paragraph. Figure Two shows how to fix this with fmt.
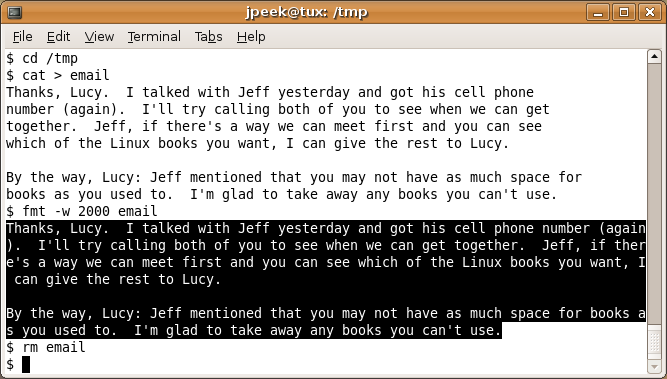
Figure Two: Flowing lines into paragraphs with fmt
The command cat > email reads its standard input and writes it to the file email. Using fmt -w 2000 outputs that file with lines 2,000 characters long (2000 is an arbitrary large number). Copy the fmt output with your mouse and paste it into the other GUI. (Note that fmt normally outputs two spaces at the end of a sentence. If you want a single space instead, pipe fmt‘s output to tr -s ' '.)
Two more notes before we wrap this up: GNU fmt has several options to control formatting. There are alternatives to fmt, too, including scripts in languages like Perl that handle formatting the way you want it.
Jerry Peek is a freelance writer and instructor who has used Unix and Linux for more than 25 years. He's happy to hear from readers; see http://www.jpeek.com/contact.html.