Linux data often comes in streams of bytes or lines of text. The October 2004 “Power Tools” column presented some ways to edit data byte-by-byte. This month, let’s look at tools and techniques for slicing and dicing data in words and lines, including grouping arguments with xargs and fmt, other uses of fmt and fold, joining lines with join, and turning lines into tables with column and printf.
There’s a lot to cover this month, so let’s dig in!
Groups of Arguments
Early Unix systems had limited amounts of memory, and so it was easy to “run out of room” on the command-line. For example, in a directory with hundreds of files, a command like grep“some words”*, where the * wildcard expands into all of the names in the directory, often gave an error like Arguments too long. But even on modern systems without similar limitations, it is still very useful to understand the problem and to be able to work around it.
Let’s start with a quick review of how a shell executes a program, passes command-line arguments to it, and handles its standard I/O.
When a shell executes a command line like this one.
$ grep "some words" * > /tmp/grepout
. the shell first parses the command line. The first word is the name of the program to execute; the shell finds the executable program at (in this case) /bin/grep. The quotes around some words tell the shell not to split the string into two separate arguments at the space (so the first argument to /bin/grep is the string some words, with the space and without the quotes). The shell then expands * into the names of all entries in the current directory, then (assuming there aren’t too many) passes them on to grep. The remainder of the command-line, > /tmp/grepout, redirects the standard output of the grep process to the file /tmp/grepout instead of to the terminal.
Figure One shows the resulting processes. If there are 999 files in the current directory, the shell passes grep 1,000 arguments. The first argument is the pattern to search for and the remaining 999 are filenames. (Actually, grep gets 1,001 arguments, where the very first argument is grep’ s name or its pathname.)
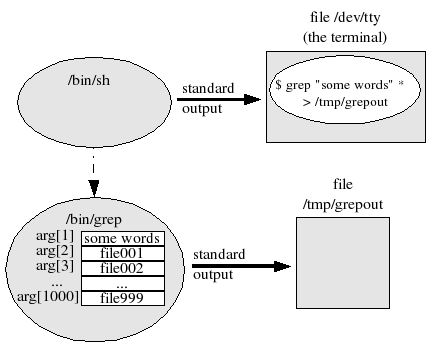
If 1,000 arguments is “too many,” the shell won’t start grep; instead, the shell will print an error. To solve this, you can run grep more than once — each with a subset of the names from the current directory — so that all of the names don’t all appear on a command line at once.
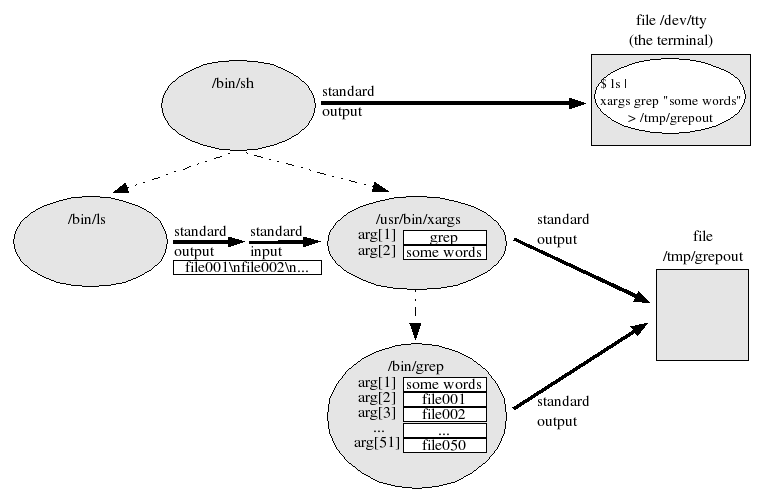
One answer is to use xargs and pass the long list of arguments to its standard input (stdin). Figure Two shows this setup. xargs reads some of the arguments — the first 50, for instance — and executes the command grep“some words” with those 50 filenames. Then xargs reads another 50 arguments from its stdin and executes grep “some words” again with those 50 filenames. The shell has redirected the standard output of xargs to the output file /tmp/grepout; all the subprocesses of xargs (the child grep processes) also inherit the same standard output, and write their results there in sequence. So the effect is the same as the original command line, albeit with a lot of extra “plumbing.” If you aren’t familiar with how the shell arranges processes, it’s worth some study.
Now, back to xargs itself. By default, xargs reads data and arranges it into an unspecified number of “chunks.” You can control how much data xargs reads per chunk with its command-line options -l max-lines (or, with GNU-style options, --max-lines= max-lines) and -n max-args (--max-args= max-args). There are more options, too, and the manual page lists them. But let’s move on to other ways to group data.
Data Chunking with fmt
Linux has more-general tools for reorganizing data, and one is fmt. fmt reads words (separated by spaces and newlines) from its standard input and collects them into lines of data — by default, about 75 characters per line. Listing One shows an example of this“ wrapping” text.
% cat messyfile
The fmt utility reads
text
from stdin and writes it to stdout in
uniform “wrapped” lines. A
series of options let you control the formatting.
%
% fmt messyfile
The fmt utility reads text from stdin and writes it to stdout in
uniform lines. A series of options let you control the formatting.
One not-so-obvious use of fmt is to “un-wrap” paragraphs from Linux text files. Typical Linux paragraphs have newline-separated lines of text, each less than 80 characters (which was the width of an old “glass teletype” terminal screen). These “hard-wrapped” paragraphs don’t fit well into a traditional word processor, which expects a newline after each paragraph instead of after each line. fmt can handle this if you use its -l (lowercase “L”) option to set a long line length — 2000 characters, for instance. fmt will read and collect words from its input until it sees two newline characters in a row (which is how Linux text files delimit paragraphs). It then emits all of the words followed by a single newline. (Also see the notes in the sidebar “fmt Versus fold.”)
Another not-so-obvious use of fmt is to gather command-line arguments as xargs does. For instance, you can simulate xargs with fmt and a shell while loop like this:
$ ls | fmt |
> while read args
> do grep “some words” $args
> done > /tmp/grepout
This command-line sleight-of-hand uses a while loop with its standard input coming from a pipe (from ls|fmt) and its standard output redirected to a file. (The May 2004 column “Great Command-line Combinations” explains redirecting loop I/O.) The effect is the same as Figure Two, except that the shell is taking the part of xargs: reading a “line” of arguments (about 75 characters) from fmt and passing it to grep via the read built-in, which reads one line and stores it in the shell variable args. This technique is better than xargs when you need more control over how the arguments are handled. For instance, you might want to test each argument and do different things with particular arguments.
By the way, using xargs and fmt in this way assumes that none of the filenames contain space, tab, or newline characters. Those characters are all legal in a Linux filename. If this might be a problem in your application, use a different setup. For example, the GNU xargs option -0 (the digit zero) or --null specifies a list of filenames separated by ASCII NUL characters. This is meant to be used with the command find -print0, which write lists of names separated by NULs.
Joining Lines with join
The join utility does relational database-like operations on lines of text. For each pair of input lines with identical join fields, join writes a joined line to standard output. (Input lines should typically be sorted on the join field.) Let’s see a simple example.
Your directory has three data files. It also has an“ index” file named filelist that describes each of those files. Listing Two shows this.
$ ls -l
total 16
-rw-r-r- 1 jpeek users 54 2005-03-15 11:14 a.out
-rw-r-r- 1 jpeek users 2252 2005-03-15 11:14 b.txt
-rw-r-r- 1 jpeek users 5 2005-03-15 11:19 c.xyz
-rw-r-r- 1 jpeek users 36 2005-03-15 11:20 filelist
$
$ cat filelist
a.out Executable file
b.txt Text file
c.xyz A file
join expects two filename arguments, say, f1 and f2. One of the arguments can be a dash (-), which means “take this file from the standard input.” (To join more than two files, use join multiple times in a pipeline.)
Here, you want to join on the filename — that is, the line of ls -l output that contains a.out should be joined to the corresponding line from filelist. By default, join expects to join on (to match) the first space-separated field in each line. But, in the ls output, the filename is in field 8 (where the first field is number 1). To specify the join field number for f1, use the option -1. (In the same way, for f2, use -2.)
Listing Three shows the result.
$ ls -l | join -1 8 - filelist
a.out -rw-r-r- 1 jpeek users 54 2005-01-02 11:14 Executable file
b.txt -rw-r-r- 1 jpeek users 2252 2005-01-02 11:14 Text file
c.xyz -rw-r-r- 1 jpeek users 5 2005-01-02 11:19 A file
By default, join only outputs lines with matching join fields. So there’s no output from the first and last lines of ls -l. (The -o option controls which fields from f1 and f2 are output in which order. See the info page for join for details.)
Because join outputs a single space (by default) between each field, the neat columns from ls -l are partly jumbled. Let’s look at two ways to fix that: column and printf.
Making Columns with column
column reads input from files or standard input and writes it in multiple columns. There are several options available, and you can get the details with man column.
Let’s use the -t option, which reads each line of input, finds the width of each space-separated field, and arranges all of the fields into a tabular format where each column is just wide enough for every field it contains. Listing Four shows the result.
$ B
a.out -rw-r-r- 1 jpeek users 54 2005-01-02 11:14 Executable
file
b.txt -rw-r-r- 1 jpeek users 2252 2005-01-02 11:14 Text
file
c.xyz -rw-r-r- 1 jpeek users 5 2005-01-02 11:19 A
file
By default, column -t puts two spaces between each column. Here, each word from filelist has been put into a separate column. This isn’t quite perfect yet, so let’s look at printf.
Outputting Arguments with printf(1)
If you’ve written programs in C and some other languages, you’ve probably used printf to write output in a particular format. There’s also a GNU command-line printf, as well as versions built into shells like bash and zsh, which all work in about the same way. printf reads a format specification from its first command-line argument. (Details are in the printf(3) manual page.) Then it writes its other arguments in that format.
Here, let’s use the shell’s read built-in to read each line from a redirected-input while loop, let the shell break each stored line at spaces when it expands the stored value from read, and use printf to output those arguments neatly. (You could do the same thing with a little script in some language such as Perl that reads each input line and writes it with that language’s printf.) We don’t want all of the fields from the join output, so we use only some of the stored shell variables.
Listing Five shows the setup and the result.
$ ls -l | join -1 8 - filelist |
> while read file perm link user group size date time desc
> do printf '%s %s %s %4s %s\n' $file $date $time $size “$desc”
> done
a.out 2005-01-02 11:14 54 Executable file
b.txt 2005-01-02 11:14 2252 Text file
c.xyz 2005-01-02 11:19 5 A file
Notice the quotes around “$desc” to keep the shell from splitting its multiple-word contents into separate printf arguments.
Jerry Peek is a freelance writer and instructor who has used Unix and Linux for over 20 years. He’s happy to hear from readers; see https://www.jpeek.com/contact.html.