When you look at the menus and buttons of graphical applications, you can’t see one of the great strengths of Linux systems: using the names of files and directories as a simple kind of database. Shells and utilities can add another dimension to this organization scheme.
This article isn’t only for command line users. These techniques work for graphical applications, too. For instance, you might set up the files with the quick command-line tools, then access the files from the GUI app. (The next two columns will have details.)
Linux filesystems in brief
This section has four basic points to bring everyone up to speed on filesystems. (The second point, about pathnames, is worth reviewing.)
- Files’ names are contained in directories — which are actually files themselves. A directory is an (unsorted) list of filenames and meta-information. There are two main ways to list the files in a directory:
- Utilities like ls (which has some surprisingly powerful features) and find read directories, then analyze and output information from them.
- Shell wildcard operators like
*and[x-y]read directories and output sorted lists of matching filenames.
- The filesystem is an (inverted) tree of directories and other entries. The top entry is the root directory, which is named simply /. To locate a filesystem entry, you give its pathname. There are two kinds of pathnames:
- A full or absolute pathname. These start at the root directory; they always begin with /.
- A relative pathname. These start at the current directory; they never begin with /.
Let’s say your current directory is /home/zoe and you’d like to open the file named bar in the subdirectory named foo. You could use either the absolute pathname /home/zoe/foo/bar or the relative pathname foo/bar. (The relative pathname does not start with the current directory name! That’s a common mistake.)
- Filenames starting with a dot (
.) aren’t shown by ls (unless you use its-aoption) and aren’t matched by shell wildcards (unless you type the dot explicitly or set a shell option). Every directory has two special entries:- A single dot (
.), which is another name for the current directory. - A double dot (
..), which is another name for the parent directory (the directory that contains this directory).
- A single dot (
- Linux filesystems have almost no rules about names of filesystem entries except that they can’t contain slash (/) or NUL (all-zero byte) characters. Some characters can cause trouble, though, because shells use them. For instance, shells use space characters to separate arguments. Good programming technique avoids these problems. To find out more, read Filename Trouble.
Systems of directories
One way to organize data is by putting it into a database — for example, MySQL. Before databases and GUIs were as common as they are today, though, another way to store data was to put it in files that you handled with programs like sort, grep and join (a little-known utility you can read about in More Data Surgery).
Another “old” technique is still very useful today. The directories and the files in them can become a simple database themselves. Doing this lets you avoid using formal databases in some cases — which can make your data more accessible because you don’t need to run a database query to find what you want. Any application — graphical or command-line — can access the data simply by opening the right file(s).
Here’s a fairly obvious example to show the idea. You want to store system logs in a way that makes them easy to find. So you create a directory named, say, /data/logs. Underneath, create a directory tree organized by year, month, and date. For instance, the directory /data/logs/2008/06/23 would contain log files from June 23, 2008 — syslog, mail.log, and so on. Because each day’s files are stored in a separate directory, all files of a particular type can have identical names — for instance, httpd — as the next example shows.
How could you count the number of web server hits during each day of June, 2008? wc -l counts lines. So the command wc -l /data/logs/2008/06/*/httpd would pass 30 arguments to wc: /data/logs/2008/06/01/httpd, /data/logs/2008/06/02/httpd, and so on, up to /data/logs/2008/06/30/httpd. (When wc gets multiple filename arguments, it outputs a separate count for each file.)
Passing many long pathnames to a utility can be inefficient. For the simple example above, giving wc relative pathnames could be better:
$ cd /data/logs/2008/06 $ wc -l */httpd
If you wanted to use a script in Perl, Python, ., instead of wc, you could iterate through the list of filenames, opening each in turn and doing whatever operation to it. From a web server with a language like PHP, build a pathname to the proper file(s), then open and read them. The filesystem tree organizes data without a formal database.
Organizing files by date, as we did here, is a simple example. To
make more complex systems, think what characteristics the files have
in common and what’s different. For example, if there are four main
types of files, and each type has ten subtypes, you might make four
top-level directories and ten subdirectories in each. If you can give
those subdirectories consistent names, you’ll make it easy to navigate
the tree with the shell or from a GUI application’s menu. You’ll also
make it each to pull out particular data using wildcards and utilities.
File-naming systems
You can use filenames — as well as directory names — to organize data in another way. Shell wildcards, and utilities like ls and find, let you choose particular files by some or all of the characters in their names or by their locations in the filesystem.
Let’s take a look at a naming system based partly on filenames.
The directory structure in the previous section could be flattened into a single directory by using filenames like this: type_year-month-date
For example:
httpd_2008-06-01 ... httpd_2008-06-30 httpd_2008-07-01 ... mail_2008-06-01 mail_2008-06-02
The fields in each filename are mostly constant-length and are separated by
consistent characters that make pattern-matching easy.
This lets you use (for example) shell wildcards to grab the files you want:
httpd_2008_06*gives all httpd files from June, 2008,httpd_*-06-*is all httpd files from every June,*-01all files from the first day of any month,*-0[147]-* *-10-*all files from the first day of every quarter (January, April, July and October 1),*_2008-*all files from 2008.
(Of course, wildcards can’t handle every case. But a few lines of code in a scripting language probably can.)
Read the files or pass those selected arguments to a utility like grep to search for matching data, cut to retrieve certain columns or fields, join to perform database-like operations, paste to reassemble data in different order, write a script of your own, or. well, you get the idea.
Naming schemes like these aren’t only useful on the commend line. You can also find the file you want by opening the directory from the menu of a GUI application and scrolling through the names.
Although Linux directories can have many thousands of entries, a system like this can get unwieldy if it’s “too big”. That’s when combining directory — and file-naming schemes can help.
File and directory systems
I (Jerry) have more than 50,000 photos. More than half were originally negatives or slides, and I’ve since made digital versions of all of those with a quick “scanning” system. My digital camera churns out thousands more photos per year — and many photo come as a pair of files (either RAW and JPEG, or full-size and thumbnail).
To organize them, I started by looking at photo organizing software — GUI systems that supposedly make finding photos easy. But handing my 500+ Gigabytes of data, with multiple versions of most photos, made me nervous no matter how flexible (and well-programmed) the system seemed to be. Since I knew the Linux filesystem and tools so well, and they’d been battle-tested by years of heavy use, I decided to make my own filesystem-based photo organizer.
One big advantage of this was that I’d be able to choose which tools I wanted to use to edit and name the photos — not just the tools in a somewhat-limited photo organizing package. This let me name my files any way I wanted to. And I could use flexible image tools such as ImageMagick (read more here, here, and here) that would let me handle hundreds of images from the command line, or with scripting languages, by writing a few commands or lines of code.
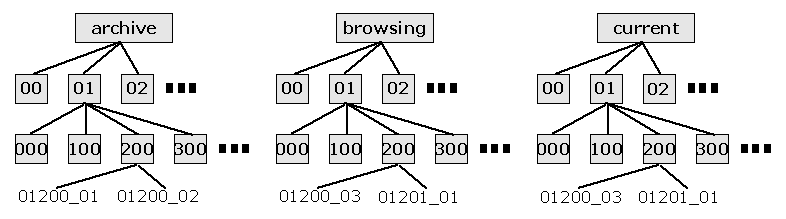
Figure 1: Simplified view of filesystem-based photo organizer
Figure One shows selected parts of the structure I’m using. Several levels, and most entries from the levels I’ve shown, are missing. You may never want to make a system like this — even for photos — but the ideas behind it could help you with other systems.
- The entire 500-Gigabyte tree is too big to fit on any of my filesystems. So it’s spread across several filesystems (which are cross-mounted on a Microsoft Windows system, by the way, so I can use Windows-based tools when I need them). The actual pathnames start with /j/pix/archive/, /e/pix/browsing/, /e/pix/current/, and /j/pix/current/. (A directory tree can’t span physical filesystems. Adding a “front-end” tree of symbolic links could work around that problem.)
- The top-level directories are:
- current, with the most up-to-date full-size images (some larger than 5000x4000 pixels)
- browsing, with reduced-size versions of the photos from the current tree.
These files, made with the ImageMagick convert utility, are just large enough to fit my screen and were saved at a JPEG quality setting of 50%. It’s much faster to browse through these photos than the full-sized versions in the current tree.The relative pathnames are identical in both trees — for example, the photo browsing/01/200/01200_03 is a small version of current/01/200/01200_03. This makes it easy to find the corresponding full-sized photo — and vice versa. (Figure One shows shortened filenames. See below.)
- archive, for older images that I don’t normally need. For example, if I’ve “cleaned up” a photo, I’ll save the edited version in current and move the original to archive.
- The tree currently has two levels of numbered directories. The top level is numbered in thousands: 00 for photos 1 through 999, 01 for photos 1000 through 1999, up to 50 for photos 50000 through 50999. Each top-level directory has ten “hundreds” subdirectories, 000 through 900.
Note: Consistent directory name length is important. To sort correctly with shell wildcards, all numbered directory names should be the same length — that is, have the same number of digits. (If some directory names had two digits, like 00, 10 and 11 — and others had three digits, like 100 and 101 — the shell’s lexicographic sorting would put 101 before 11 and 111 before 20. Using constant-length names, with leading zeroes, avoids that problem.)
The tree contains only 50,000 unique photos now. Once it tops 99,999, I’ll probably add a new upper level divided by hundred thousands.
- The files themselves are in the “hundreds” directories.
- Filenames shown at the bottom of the diagram have been shortened to
save space. The actual filenames start with seven digits, an underscore
(
_), and a two-digit suffix. The suffix is a version number. The original version of a photo has suffix _01, the second version has _02, and so on. So, for instance, the first version of photo number 1200 is in a filename that starts with 0001200_01.
And the second verison of photo 12345 would be stored at 12/300/0012345_02.
All filenames end with an extension to identify the file type. (That’s actually not always needed, thanks to magic numbers and the file(1) utility. But it’s also useful for finding files of the same type, like *jpg.)
Filenames can also include other meta-information. Here are three
sample filenames that show how more meta-information can be included in
the name, if you’d like:
0012345_03_2568x3915-104x160_lzw.tifis photo 12345, version 3. It has two images (TIFF “pages”); the first is 2568 pixels wide and 3915 pixels high, and the second is 104x160 pixels. It’s LZW-compressed in TIFF format.0012345_04_2568x3915_q75.jpgis photo 12345, version 4, 2568x3915 pixels, saved at 75% quality as a JPEG.0012345_04_gimp-curvesis the exported Curves file from the GIMP photo editor that was used while editing photo 12345, version 4.
Because all of the filenames start with the photo number, it’s easy to match photo 12345 using wildcards: 0012345*, or something like 0012345*.??? (to grab the image files — names ending with a dot (.) and three characters (the “extension”). If I needed only original photos (version 1), a wildcard pattern like ???????_01* could do the job. (Of course, something other than wildcards is a better file-picking choice sometimes.)
I also keep a set of spreadsheets (which could be converted into a database) with more information about each 1000 unique photos: all versions (suffix numbers), the date, the subject, location, settings used to create or edit each version of the photo, and more. This makes it easy to find, say, all photos taken in a country or in a particular month. Some of this imformation may be saved in some image files as EXIF data or IPTC profiles, for instance. But having it available in a quickly-read format — as part of the filename or in a simple database — avoids having to read and parse each file to get meta-information. (That’s especially useful when you’re searching for a particular file, and you don’t want to open Gigabytes of photo files to find data corresponding to a particular image whose number you don’t know.)
Of course, if you’re setting up your own system, you can use whatever system of naming, numbering and metadata that works best for you! This system is just an example.
In Part Two, we’ll see ways to make systems of files and directories. Part Three will cover some ways to access them.
Jerry Peek is a freelance writer and instructor who has used Unix and Linux for more than 25 years. He's happy to hear from readers; see https://www.jpeek.com/contact.html.